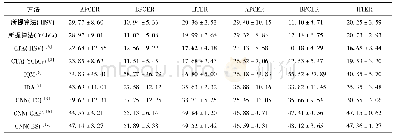
《表4 错误分类样本的比例 (%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
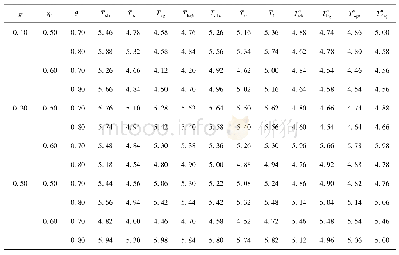
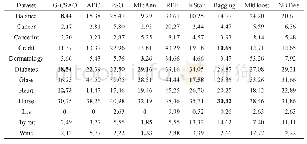
从表4中可以看到,54.4%的因果关系类样本和34.3%的解说关系类样本被TLAN模型错误地识别为了并列类,这说明错误主要是出在判断一个样本是不是并列关系上。这主要是由两个原因导致的:(1)训练集中的并列关系类样本超过半数;(2)许多论元之间虽然不是并列关系,但是语义上很相似。例2给出了一个这样的例子。
| 图表编号 | XD0070611400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 徐昇、王体爽、李培峰、朱巧明 |
| 绘制单位 | 苏州大学计算机科学与技术学院、江苏省计算机信息技术处理重点实验室、苏州大学计算机科学与技术学院、江苏省计算机信息技术处理重点实验室、苏州大学计算机科学与技术学院、江苏省计算机信息技术处理重点实验室、苏州大学计算机科学与技术学院、江苏省计算机信息技术处理重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}