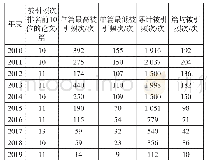
《表1 高被引论文在网络平台的被提及情况统计表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
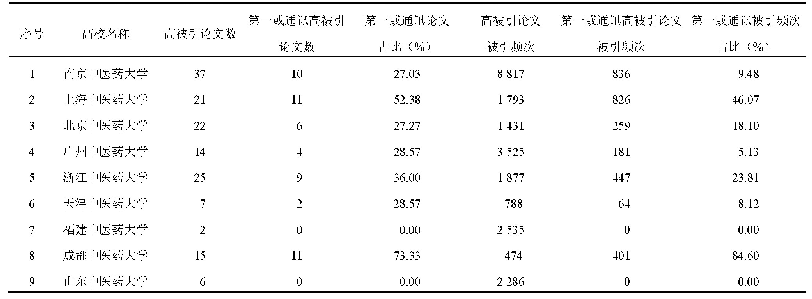
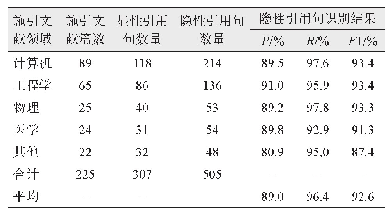
《基于中文期刊高被引论文的Altmetrics指标评价体系研究》
通过将文献数据中的题目和作者作为网络爬虫抓取的条件,以百度(www.baidu.com)为目标网站,获取其搜索结果页面的URL并进行解析分析。在百度搜索的结果中,排名靠前的搜索结果的相关性要高于排名靠后的,为提高爬虫效率和有效性,笔者仅对百度搜索结果的前30条进行抓取。将爬虫层级设定为两层,一层是自动抓取百度搜索结果列表页的URL,另一层是依次抓取列表页内各个搜索结果的URL,经过上述的两层挖掘,可以抓取到相关搜索结果页面的URL,通过对URL的域名字段进行解析,可以得出相应的网站出处。在完成所有文献数据的网络抓取操作后,以网站出处作为统计分析的分组标签,分别统计在其中追溯到的文献篇数,并计算该网站追溯到的文献数在本次研究文献总数中的占比情况。最终得出高被引论文在网络平台的被提及情况统计表,如表1所示。
| 图表编号 | XD0070463300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.05 |
| 作者 | 张瑶 |
| 绘制单位 | 天津师范大学图书馆 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}