《表1 数据集字段描述:基于数据库知识发现的员工流失预测》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
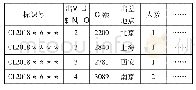
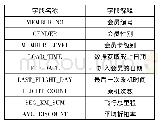
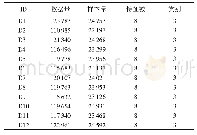
本文数据取自于Kaggle竞赛网站的公开数据集[16],原始数据集包括含“Age”“Attrition”等35个字段的1 470条样本,其中无缺失值。由于原始数据集中某些字段,如“DailyRate”“EmployeeNumber”并无实际意义,再如“Over18”“StandardHours”等字段所有样本均取相同值,因而对分类结果不会造成差异性影响,首先删除该些无效字段。保留下来的用于模型训练的28字段描述如表1所示,其中“Attrition”为二分类预测变量,正负例比为237∶1 233,其余为输入特征变量。
| 图表编号 | XD0069262900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.25 |
| 作者 | 吴丹 |
| 绘制单位 | 同济大学经济与管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}