《表4 不同方法的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
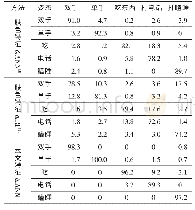
表4中方法E代表只使用分支1训练,方法F代表使用分支1、分支2一起训练,方法H代表分支1、分支2、分支3联合优化,方法J代表分支1、分支2、分支3、辅助分类层一起训练。本来辅助分类层只在训练时使用,在测试时不使用,后来研究者发现在测试时加上辅助分类层提取的特征后Rank1提高了0.7%,mAP提高了1.3%,故研究者在后面的实验测试时均加上辅助分类层提取的特征。表4中方法F的Rank1和mAP比方法E分别提高了3.3%和8.2%;方法H的Rank1和mAP比方法E分别提高了3.4%和9.1%。方法J是基于本文所提出的完整模型的方法,方法J的Rank1和mAP比方法E分别提高了4.7%和10.9%。这是因为方法J的模型能够对行人提取更丰富的特征,减少了训练过程中的信息丢失,比方法E(单一的全局特征)更有辨别力。表4中基于辅助分类器模型的方法J比方法H的Rank1和mAP分别提高了1.3%和1.8%。可以看出,每个分支对提高实验结果都是有效的。上述实验均是基于Market1501数据集进行的。
| 图表编号 | XD0066621900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.25 |
| 作者 | 潘通、李文国 |
| 绘制单位 | 昆明理工大学机电工程学院、昆明理工大学机电工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}