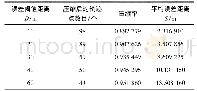
《表1 快速算法所得-logp的阈值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
相比于Piepho仅模拟了200个个体的10 000个标记,我们借助Balding-Nichols模型[12]模拟样本大小分别为50、100、200、500、1 000、2 000和5 000的10万个基因型数据,根据基因型数据,模拟出加性遗传效应,从而模拟出表型值,假定每个个体只有一个性状。数量性状的表型值与标记遗传效应之间的关系可以用简单线性回归模型来描述,从而每一个统计量都用简单线性回归的表型来计算。每个样本都重复模拟1万轮次。采用快速逼近法和置换检验法检验10万个标记并计算了近似和准确的临界阈值。当显著性水平为0.05(0.01)时,从置换检验后获得的统计量的顺序确定[13]准确临界阈值,即表型值重排后,表型和基因型的关系随机打乱,每次得到一个p值,将这些值从小到大排列,第95%(99%)就为准确临界阈值。相应的置信区间分别为93.7%和96.4%(98.7%和99.4%)。为了与文献结果[9]进行比较,将拒绝零假设的百分比视为I型错误率。利用置换检验方法(空跑)得当logp的阈值和检验所得统计量的阈值,然后用快速算法模拟出相应结果。具体模拟结果见表1和表4。
| 图表编号 | XD0065082300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.20 |
| 作者 | 野金花、方铭、徐艳、高德宝、周晓晶、张巧生、张莹 |
| 绘制单位 | 黑龙江八一农垦大学理学院、黑龙江八一农垦大学理学院、黑龙江八一农垦大学理学院、黑龙江八一农垦大学理学院、黑龙江八一农垦大学理学院、黑龙江八一农垦大学动物科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}