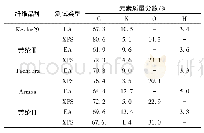
《表1 网络结构及参数设置》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
要训练一个足够准确的网络需要大量的标注好的数据,我们准备了两个数据集:合成数据集和增量数据集。通过图像混合模型[19]从正常视频帧序列中生成足够的剧变和渐变样本数据,然后将初始的合成数据集用于训练,并得到初步的分类器模型。然后用得到的分类器模型对未标注数据进行预测,从中选出结果正确的数据集作为增量数据集。重复上述过程直到网络模型误差足够小,再利用最终的数据集训练得到性能更优的分类器。最终我们得到的数据集共包括249,411个视频片段,其中包括192,321个剧变和渐变视频片段,每个视频片段由16帧图像序列组成。在此基础上再去调整模型参数得到我们所采用的网络模型。具体的网路结构及参数设置如表1所示。
| 图表编号 | XD0061663600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.05 |
| 作者 | 郝小龙、冯敏、樊强、彭启伟、韩斌 |
| 绘制单位 | 南京南瑞信息通信科技有限公司、南京南瑞信息通信科技有限公司、南京南瑞信息通信科技有限公司、南京南瑞信息通信科技有限公司、南京南瑞信息通信科技有限公司 |
| 更多格式 | 高清、无水印(增值服务) |




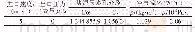
{kind=link}