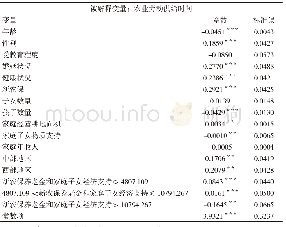
《表1 样本概览:老年贫困特征及政策含义——基于CHARLS数据的分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《老年贫困特征及政策含义——基于CHARLS数据的分析》
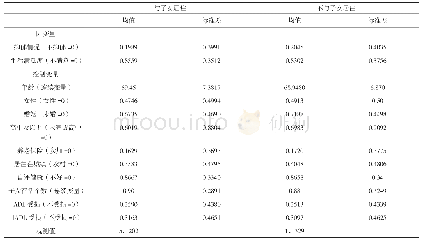
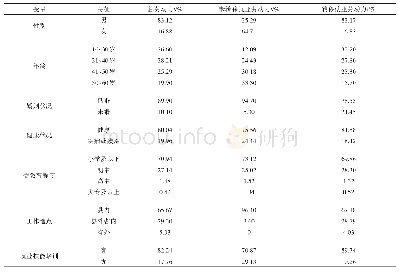
本文数据来源于中国健康与养老追踪调查(CHARLS)2011年、2013年和2015年的调查,我们感兴趣的是基于同一筛选标准、可以重复观察的相同样本。三个年份的调查都在不同程度上含有缺失和异常的数据,全球老龄化数据平台(Gateway to Global Aging Data)按照RAND Health Retirement Study的标准对2011年和2013年的原始数据进行了清理(1),2015年的数据平台没有进行清理,作者依据平台公布的2011年和2013年编码表和清理手册,按照同一标准对2015年的数据进行了清理[18]。家庭数据根据家户成员身份编码匹配到每个个体样本上,以此计算出人均数据。其中,数据中包含零值的样本被放弃,因为这些零值既有可能是真实的(即被访者完全没有收入、消费或资产);也有可能是谎报的(即被访者不愿意说出实情),基于问卷填写的结果我们无法区分“真实的零值”和“谎报的零值”。此外,有些样本2011年出现,2013年消失,但2015年重新出现,在贫困波动性分析中这些样本被放弃,因为我们无法判断这些样本在2013年时是否属于贫困。表1列出了清理后的等于和大于60岁的有效样本分布情况。从收入数据看,44.57%的样本只有一个年份的信息,33.29%有两个年份的信息,22.13%有三个年份的信息。从消费数据看,对应的样本比例分别为46.14%、33.84%和20.02%。从资产数据看,对应的样本比例分别为51.71%、31.84%和16.45%。样本具体情况见表1。三个年份的同一类别数据的核密度估计均显示出较为一致的离散趋势(见图1),说明采用的数据清理方法可靠,据此得出的测算结果的可信度强。
| 图表编号 | XD0056228800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.25 |
| 作者 | 李萌、陆蒙华、张力 |
| 绘制单位 | 上海海事大学科技处、复旦大学人口研究所、复旦大学人口研究所 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}