《表1 本文数据集:基于多开发者社区的用户推荐算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由于本文算法所需数据基于开发者社区中的用户行为,需要利用用户与用户之间的关系信息以及用户与标签之间的偏好信息进行实验,因此通过抓取开发者社区中的所有有效问题,以获得有意义的用户在开发者社区中的行为信息.本文使用Python中的工具Scrapy进行开发者网站中的数据抓取工作.首先收集开发者社区中的标签信息,通过标签进行初步筛选,爬取在本文标签分类下每类标签包括的问题信息;进一步,爬取每个问题下所有用户的参与行为,统计用户与用户和用户与标签的信息;最后,在获得用户有效信息之后,通过数个预处理方法对所获数据进行标签语义处理,包括根据问题评分进行有价值的主题筛选与有效用户分类等,得到用于实验的有效数据集.本文数据集见表1,本文收集的数据包含截止到2017年10月的Stack Overflow以及Github两个社区中的共计117个标签下约140万有效主题贴.对所有主题贴统计参与其中的用户,并排除无法作为推荐参考的游客账号以及类似google的大型公共账号,累计获得两个开发者社区中的约40万有效注册用户的id及其在有效问题下的活动信息.
| 图表编号 | XD0056218400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 时宇岑、印莹、赵宇海、张斌、王国仁 |
| 绘制单位 | 东北大学计算机科学与工程学院、东北大学计算机科学与工程学院、东北大学计算机科学与工程学院、东北大学计算机科学与工程学院、北京理工大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |


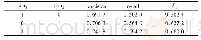



{kind=link}