《表2 数据库统计信息:采用拼音降维的中文对话模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
将建立的数据库以1 000∶1的比例分为训练集和测试集两部分,其中训练集用于训练对话模型,测试集用于验证对话模型的效果。为了作进一步分析,对建立的中文对话数据库进行了统计,统计结果如表2所示。
| 图表编号 | XD0054909700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 吴邦誉、周越、赵群飞、张朋柱 |
| 绘制单位 | 上海交通大学自动化系系统控制与信息处理教育部重点实验室、上海交通大学自动化系系统控制与信息处理教育部重点实验室、上海交通大学自动化系系统控制与信息处理教育部重点实验室、上海交通大学安泰经济与管理学院管理信息系统系 |
| 更多格式 | 高清、无水印(增值服务) |


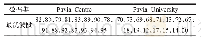



{kind=link}