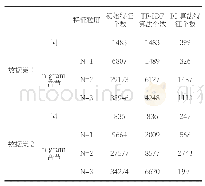
《表3 基于全谱降维的四唑类化合物分类结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于激光诱导击穿光谱和拉曼光谱对四唑类化合物的快速识别和分类实验研究》
支持向量机(SVM)是监督学习中最有影响力的方法之一,在解决小样本、非线性及高维模式识别中具有很强的分类学习能力[28],非常适合本文中判别模型的建立。在每个样品的50组光谱数据中,随机选取35组作为训练集,剩余的15组作为测试集。模型建立及预测步骤如下:(1)以PCA降维后获得的训练集光谱数据的主成分得分作为SVM模型的输入变量,以样品的类别标签值为输出变量;(2)选取应用最广泛,且其对非线性问题有较好处理能力的径向基函数(Radial Basis Function,RBF)作为核函数;(3)通过网格搜索法优化惩罚因子c和核参数g,从而确定最优的分类超平面,c和g分别为1.3和5.2,建立分类模型;(4)将测试集光谱数据输入模型验证,最终模型分类准确率为100%,如表2所示。此外,本文还将全谱6 144个变量直接进行主成分分析,然后提取前64个主成分,其累计解释率为98.3%,基于SVM算法进行分类研究,结果显示这种方法不仅计算量大,而且最终平均分类准确率仅为88.3%,如表3所示。通过两种方法的对比发现,对于本文中4种四唑类化合物的分类模型的建立和预测,选取差异较为明显的特征谱线为变量,并结合PCA-SVM算法可以得到较好的分类结果。
| 图表编号 | XD0082398300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 王宪双、郭帅、徐向君、李昂泽、何雅格、郭伟、刘瑞斌、张纬经、张同来 |
| 绘制单位 | 北京理工大学物理学院、北京理工大学物理学院、北京理工大学物理学院、北京理工大学物理学院、北京理工大学物理学院、北京理工大学物理学院、北京理工大学物理学院、北京理工大学爆炸科学与技术国家重点实验室、北京理工大学爆炸科学与技术国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}