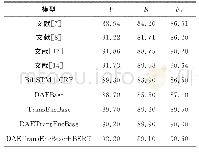
《表2 在开发集上CNN不同参数获得的宏平均F1值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
参考Xu等[18]提出的TMN模型,将词向量维度设置为300,词性向量设置为50维。其中词向量使用在维基百科中文语料库上预训练好的词向量。除了词向量之外的参数都随机初始化。为了避免过拟合采用dropout策略,dropout设置为0.5。在开发集上通过网格化搜索来取得最佳的参数,之后合并训练集和开发集作为新的训练集对模型进行训练,并在测试集上评估模型。在编码层Bi-LSTM神经元设置为50维,根据表2得到的实验结果,把CNN卷积核数量设置为1 024,卷积核窗口大小为2。表3是不同GMN层次的实验结果对比,实验结果表明使用3层GMN的模型整体效果更好。
| 图表编号 | XD0054901000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 王体爽、李培峰、朱巧明 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}