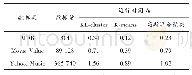
《表2 Spark与Kafka+Spark集群对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Spark Streaming的电力流式大数据分析架构及应用》
实验环境包含1个Master和2个slave节点,每个节点2Core。测试数据来自testdata.csv。设置Spark Streaming的处理间隔为1 s(batch time)。在Spark集群环境下,采用socket接收1 000条记录,对比实时异常检测系统(Kafka+Spark)中Kafka生产的1 000/s条记录的情况下,Spark Streaming在每个batch time内的实时处理能力(见表2)。
| 图表编号 | XD0050593600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.01 |
| 作者 | 田璐、齐林海、李青、王红、田世明、卜凡鹏 |
| 绘制单位 | 华北电力大学控制与计算机工程学院、华北电力大学控制与计算机工程学院、华北电力大学控制与计算机工程学院、华北电力大学控制与计算机工程学院、中国电力科学研究院有限公司、中国电力科学研究院有限公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}