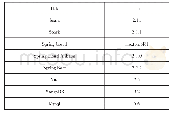
《表5 单机与Spark集群的硬件环境与操作系统》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了研究Spark框架对平台数据分析任务在性能上的提升效果,在以上实验基础上进行对比实验。对于以上每一种算法,比较在单台机器与Spark集群上进行数据训练的速度。单机与Spark集群的硬件环境和操作系统相同,但是Spark集群包含3台机器,具体配置见表5。训练样本量为80万条,进行30次重复实验,将单台机器和Spark集群的数据训练时间分为2组,进行方差齐性检验。从表6的实验结果可看出,除决策树之外,其他3种模型的方差齐性检验p值均小于0.05,即可认为逻辑回归、随机森林、梯度迭代树在2组间的方差不相等,而决策树在两组间方差相等。根据方差齐性检验结果分别进行方差相等和不等情况下的独立样本t检验,结果显示4种算法模型的检验p值均小于0.01,表明单台机器和Spark集群的训练时间均有显著差异,即Spark集群上的训练时间明显小于单台机器的训练时间,说明在Spark集群上调用并行计算方式的机器学习包可以提高数据训练效率。
| 图表编号 | XD00112472200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.20 |
| 作者 | 须成杰、肖喜荣、张敬谊、郑文婕 |
| 绘制单位 | 复旦大学附属妇产科医院、复旦大学附属妇产科医院、万达信息股份有限公司、万达信息股份有限公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}