《表3 例子中的1级表示:基于改进多层次模糊关联规则的定量数据挖掘算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
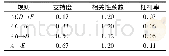
令该层次结构的两个变量μ和τ的值均为1,其中,μ表示当前项目所处的分类层次,τ表示当前频繁项目集合的项目数量。将数据库中所有μ相似的事务都合并为一个大类并将它们加和。例如,可以将项目(223,2)和(254,2)整合为(2**,4),这一任务的结果如表3所示。根据对应的隶属度函数,将所得到的组转换为模糊集的形式。以(1**,8)为例,根据图3中预定义的分类,这个组是属于人用洗护产品类的,需要使用前述的人用洗护产品隶属度函数。在这一隶属度函数中,计算结果为6,对应着低区域的隶属度为0.6,中区域的隶属度为0.9,高区域的隶属度为0.1。通过这种方式可以计算得到事务中所有项目构成的等价模糊集。在所有事务中计算每一个模糊区域值的和,得到各模糊区域隶属度之和,如表4所示。
| 图表编号 | XD003893700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 张定祥、张跃进 |
| 绘制单位 | 贵州商学院计算机与信息工程学院、华东交通大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}