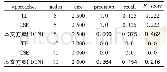
《表1 模拟数据集性能比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:1) TSC算法要求数据的维度必须不小于类别数,否则无法运行;2) FCM和SLMC仅在目标域上学习,其他算法均在两个域上学习;3) STC、TSC和TFCM算法代码均由文献[31]作者分享。
通过观察表1知,WUDA在两个模拟数据集上的性能明显优于其他算法。值得注意的是,在双月分布中,WUDA的RI和NMI指标均为100%,并且较于其他算法的聚类性能有着显著的差别,主要得益于WUDA是在输出(标记)空间上实现聚类,受输入样本的分布情况影响较小。因此,本文方法不仅能应用于传统的高斯分布数据,也对类似于双月分布的非传统分布的数据适用。另外,对比SLMC和WUDA,易知WUDA通过学习源域中的“知识”提高了目标域的聚类性能,从而验证了本文算法的可行性。
| 图表编号 | XD0036947300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 余欢欢、陈松灿 |
| 绘制单位 | 南京航空航天大学计算机科学与技术学院、南京航空航天大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}