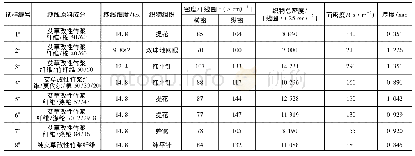
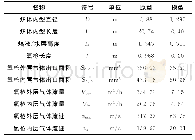
《表1 S-CNN结构及参数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于改进卷积神经网络与动态衰减学习率的环境声音识别算法》
针对环境声音识别问题,提出一种基于卷积网络的识别模型S-CNN,其网络结构如图1所示。整个网络由5个卷积层、6个BN层及1个全连接层构成,各层网络的结构参数见表1。前两个卷积层均采用6×6的卷积核,并以1为步长在特征图谱上进行内积运算,其滤波器个数设置为24。目的是利用堆叠网络增加卷积层的非线性变换,从而学习音频信号中更多的局部特征。第三、四层卷积层采用5×5的卷积核,以2为步长在特征图谱上进行内积运算,通过缩小卷积核来捕捉特征图谱的中更细微、局部的特征。同时,利用48个滤波器检测更高阶的特征组合。而为了平衡网络层数增加带来的过拟合问题,第五层卷积层并不采用堆叠策略,直接与全连接层相连。其卷积核为4×4,移动步长为2,滤波器个数为64。不同于传统的卷积神经网络,S-CNN在每层卷积层及全连接层之后并不使用池化层对输出特征向量进行降维,而是保留卷积层所提取的所有特征并利用BN层进行数据归一化处理。每层网络均以ReLU作为激活函数,以提升非线性因素。最后以softmax作为分类器,输出预测结果。
| 图表编号 | XD0036862000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.08 |
| 作者 | 冯陈定、李少波、姚勇、杨静 |
| 绘制单位 | 贵州省公共大数据重点实验室、贵州大学机械工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}