《表3 数据集大小:基于Spark的两表等值连接过程优化》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
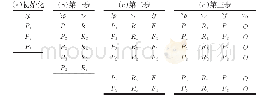
实验选用了两组数据表,每组都是两个数据大小不同的数据表(第一组数据倾斜程度低于第二组),给定的抽样率为40%分别使用本文算法和Spark的hash join算法对数据进行了关联操作,并作对比分析。两表的关联字段分别是C_RID和P_RID。数据表大小如表3所示。
| 图表编号 | XD0035715000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.01 |
| 作者 | 张子栋、郑延斌 |
| 绘制单位 | 集美大学计算机工程学院、河南师范大学计算机与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |
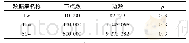


{kind=link}