《表3 基于不同采样方法的分类器性能比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
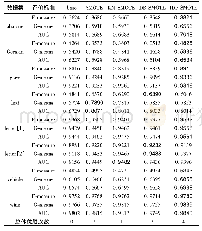
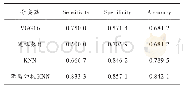
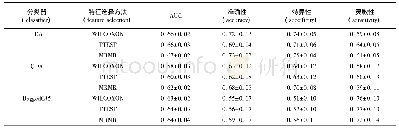
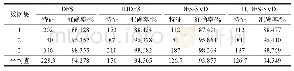
本文采用随机森林分类算法对本文提出的重采样方法进行测试和评价,并与SMOTE、KM-SMOTE和DB-SMOTE算法等升采样方法进行对比。其中,分类算法采用基于Python的scikit-learn机器学习包[12]中的标准模型和默认参数。重采样算法中,SMOTE、KM-SMOTE以及DB-SMOTE的最近邻系数均设置为k=5;设置KM-SMOTE的聚类系数c=2;设置DB-SMOTE的邻域半径ε=0.5,邻域内最少样本数MinPts=5;所有升采样算法的升采样比例均设置为β=1。分类器性能的采用F-measure、G-means和AUC等不平衡分类中常用的指标进行评价。每次实验随机选取75%的各类样本作为训练集,剩余样本作为测试集。通过100次重复实验,获得各个指标的平均值,其结果如表3所示。
| 图表编号 | XD0035695600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 盛凯、刘忠、周德超、冯成旭 |
| 绘制单位 | 海军工程大学电子工程学院、海军工程大学电子工程学院、海军工程大学电子工程学院、海军工程大学电子工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}