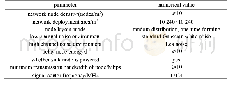
《表1 仿真参数:基于聚合度热点适应机制的网络舆情大数据收敛算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为验证本文算法性能,采取MATLAB仿真实验环境。在本次仿真过程中,自行构建了网络舆情数据集,利用文献[11]采用的爬虫方式,针对安徽省十九大、十九大一中全会热点新闻及安徽2009-2019年两会热点新闻爬取原始数据,爬取对象主要为微博、百度百家号、凤凰大风号、今日头条、主要新闻门户网站、主要中央新闻网站(人民网、新华网等)。热点匹配词汇为“从严治党”、“巡视”、“严重违纪”等反腐方面,单个匹配词汇爬取数据不低于1万条。与此同时,仿真实验采用当前常用的时间片累积挖掘收敛方案[12](Convergence Scheme for Time Slice Cumulative Mining,TSCM算法)及热点度显影收敛方案[13](Convergence Scheme of Hotspot Degree Development,HDD算法)。仿真指标采用收敛时间、聚类生成时间两个指标。在网络舆情数据集中,利用所提算法、文献[12]和文献[13]方法,分别在高密度热点及低密度热点环境下进行仿真。仿真参数表如下:
| 图表编号 | XD003426800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 孙骏 |
| 绘制单位 | 安徽职业技术学院信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}