《表3 各数据集上的运行时间Tab.3 Running time on each data set》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
s
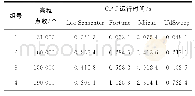
各模型在各数据集上的运行时间(t),如表3所示.由表3可知:二叉树与多叉树由于基本理论近似,所以时间的量级相同.由于经典单变量决策树算法在边界搜索中是遍历式的精确搜索,但是对全数据集仅遍历一次,所以当数据集样本数和特征数均较小时,运算速度比口袋算法建立的决策树要快一些.而当数据的特征与样本数较大时,花费时间会随之增长,且增长速度比口袋算法的决策树快,可以认为,在速度上口袋算法构造的多变量决策树具有速度优势.
| 图表编号 | XD0034181900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.20 |
| 作者 | 王子玥、谢维波、李斌 |
| 绘制单位 | 华侨大学计算机科学与技术学院、华侨大学计算机科学与技术学院、华侨大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}