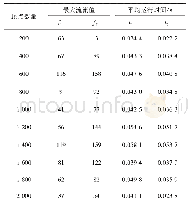
《表1 不同规模数据算法运行时间》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《大数据环境下基于Spark的Bayes分类算法研究》
实验环境是使用VMware Fusion7.0软件在1台主机上搭建了3台虚拟机,模拟Spark集群环境,集群中有一个Master节点和2个Worker节点。2个Worker节点配置都设为1G内存、1个Core。在不同数据规模下Naive Bayes算法和Naive Bayes并行流式算法在运行时间上的对比如表1所示。
| 图表编号 | XD0023038300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.06.15 |
| 作者 | 张睿敏、张琪淼、杜叔强、贾桂霞 |
| 绘制单位 | 兰州工业学院软件工程学院、兰州市公安局、兰州工业学院软件工程学院、兰州工业学院软件工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}