《表2 基于拟合阈值K的函数F2和F5的平均结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
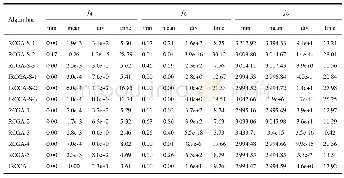
通过上文对拟合阈值的分析,若拟合阈值K过小,会产生欠拟合,反之,K越大,则过拟合,会削弱分组的意义。因此,我们选取K为0、10、20分别作用于单峰函数F2和一多峰函数F5。从表2的数据结果可以得出对于多峰函数,拟合阈值的变动不改变最终的寻优结果,但是从收敛曲线图3明显看出算法收敛到最优值的适应度值计算次数不同,K=10的时候,多峰函数更早的找到最优值。而对于单峰函数,K=0时的平均适应度值与全局最优值都是最佳的,这是由于单峰函数不存在多个最优值点,直接拟合不易陷入局部最优。之后随着K值不断增大,拟合曲线越接近目标函数曲线,因此,最终的收敛结果会更精确。由于种群经过K次迭代后的高斯拟合曲线更加接近目标函数曲线,但是,若K值无限变大,则削弱了种群分组的意义,所以为平衡拟合曲线与种群分组的作用,在本次实验中,本文确定K=10。
| 图表编号 | XD00227327600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.18 |
| 作者 | 倪婉璐、季伟东、孙小晴 |
| 绘制单位 | 哈尔滨师范大学计算机科学与信息工程学院、哈尔滨师范大学计算机科学与信息工程学院、哈尔滨师范大学计算机科学与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}