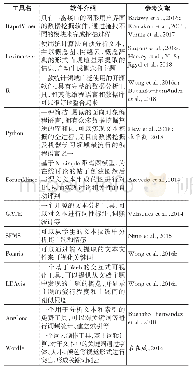
《表3 教育文本挖掘常用算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
文本挖掘算法通常可以分为两大类:一类是预测性算法,这类算法通过已有的特征值来预测未知的特征值,如各种分类算法等;另一类是描述性算法,其目的是描述概括数据中已经存在的关系和模式,如聚类、关联规则挖掘、异常检测等(Tan,2018)。除了传统的数据挖掘算法外,还有深度学习的相关算法,包括CNN(卷积神经网络)、DBN(深度置信网络)、RNN(循环神经网络)等。此外,还有一些在文本挖掘中十分重要的方法,如Word2Vec(词向量)、LDA(隐含狄利克雷分布)模型、马尔可夫模型、深度学习等。常用方法的具体描述如表3所示。
| 图表编号 | XD00227045500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.25 |
| 作者 | 刘清堂、贺黎鸣、吴林静、杨炜钦、李晶 |
| 绘制单位 | 华中师范大学教育信息技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}