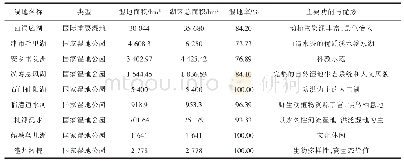
《表4 常用点格局分析函数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
点格局分析方法以植物个体的位置坐标为基础数据,将每个个体视为二维空间上的一个点,通过对空间上任意2点间的二阶特征乘积密度与随机分布状态下的值进行比较,判断2点间是否独立存在或有某种联系,常用的方法有Ripley’K函数、基于Ripley’K函数的L-函数、O-ring统计方法及双相关函数。Ripley’K函数是以点格局中某个特定点为中心、以r为半径的圆中存在点数的概率计算出来的统计量(Ripley,1977),其函数形式见表4。由于Ripley’K函数随尺度r增加自身以r2速率增加,即二次函数形式增加,会产生尺度累积效应,从而影响判别结果。为消除尺度累积效应,产生了K(r)变形后的L-函数(Besag,1977)和O-ring统计方法(Condit et al.,2000;Wiegand et al.,2013),后者以抽样点为中心,用圆环替代Ripley’s K(d)函数中的圆圈,计算环内点的平均数目,从而可孤立特殊的距离等级,消除尺度累积效应。双相关函数g(r)表达的是实际中发现2个点的概率密度与期望密度的比值,2个点的概率密度为二阶特征乘积密度,而期望密度可认为是完全随机分布格局中发现被距离r分隔的2个点的概率(Gavrikov et al.,1995)(表4)。单变量的Ripley’K函数、O-ring统计方法和双相关函数能够分析林木位置的分布格局,而双变量函数能够分析2个变量的相互关系。点格局方法在林木分布格局和林木相关性分析中运用越来越广泛,但在对其进行应用时需要考虑2个问题:一是选择合适的零模型,因为零模型决定着现实树种空间分布格局是否偏离随机分布状态以及偏离的程度(Wiegand et al.,2013);另外一个重要因素是对数据要求较高,需要林木的相对位置坐标,并进行边缘校正;此外,点格局方法计算过程相对复杂,需要专门的软件或代码支持。角尺度判断林木分布格局实质上也是一种点格局方法,不仅可用图形来描述林分中林木分布,而且还可用均值或显著性检验方法来判断林木分布格局(惠刚盈等,1999;Zhao et al.,2014),该方法并不一定需要林木定位坐标数据,通过简单的辅助工具即可获得相关数据。
| 图表编号 | XD00223847900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 赵中华、惠刚盈 |
| 绘制单位 | 中国林业科学研究院林业研究所国家林业和草原局林木培育重点实验室、中国林业科学研究院林业研究所国家林业和草原局林木培育重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}