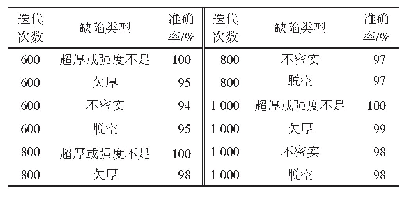
《表3 CK-means与K-means算法的迭代次数与准确率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了对比CK-means与K-means算法的迭代次数与准确率,选取iris、wine数据集随机生成各104条记录并加入少量噪声进行测试,取15次实验的平均值。如表3所示,相较传统的K-means聚类算法,CK-means算法聚类迭代次数更少,聚类准确率稍低于传统K-means算法。迭代次数减少是由于CK-means算法针对每个Canopy的数据集进行聚类,减少相似计算的数量;而CK-means算法的聚类准确率降低是由于基于Canopy对分割后的数据子集作聚类导致部分数据点分类不准确,相比迭代次数减少的加速效果,算法准确率下降的代价是可接受的。
| 图表编号 | XD00222774100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.05 |
| 作者 | 赵鑫、汪丽娟、行艳妮、赵燚、赵京霞、钱育蓉 |
| 绘制单位 | 新疆大学软件学院、新疆大学软件学院、新疆大学软件学院、新疆大学信息科学与工程学院、新疆大学软件学院、新疆大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}