《表3 监督学习在视频数据集中的表现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
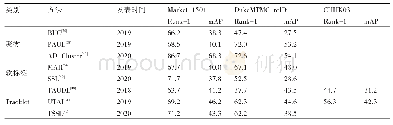
为方便对比,本文根据特征提取方式以及所采用数据集的不同分别介绍不同深度学习行人重识别模型的性能对比,包括有监督学习模型在图像数据集中的性能表现(表2)、有监督学习模型在视频数据集的性能表现(表3)、半监督/弱监督学习模型在经典数据集的性能表现(表4)、无监督学习模型在经典数据集的性能表现(表5)。从表2可以看出,有监督学习行人重识别模型在图像数据集上的准确率取得了长足进步。在Market-1501数据集上,rank-1的准确率从61.2%上升至95.7%,在Duke MTMC上,rank-1的准确率从67.68%上升至89.0%。同时还可看出,提取局部特征的模型在数据集上获取的效果普遍较好;不同数据集上不同模型的表现并不一致,研究人员仍需关注进一步提升模型的扩展性。
| 图表编号 | XD00222772900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.05 |
| 作者 | 冯霞、杜佳浩、段仪浓、刘才华 |
| 绘制单位 | 中国民航大学计算机科学与技术学院、中国民航大学民航信息技术科研基地、中国民航大学计算机科学与技术学院、中国民航大学民航信息技术科研基地、中国民航大学计算机科学与技术学院、中国民航大学民航信息技术科研基地、中国民航大学计算机科学与技术学院、中国民航大学民航信息技术科研基地 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}