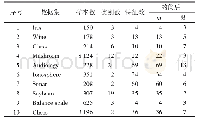
《表2 彝语实验数据集统计数据》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
标注自动化程度与训练数据质量、模型性能、质量检测和纠错方法等都有密切的关系,其中模型性能与建模是否充分结合语种特点有较大关系。云南省少数民族精准扶贫日志数据库中记录了大量访谈语音和记录数据,其中一些彝族聚集区的语音是彝语数据,这些数据包含音源基本信息(姓名、性别、年龄、地址、时间等)。从数据中抽取原始语音数据并整理对应的彝语文字,筛选部分不含其他语种、噪声少、停顿少的优质语料作为实验数据。得到的彝语语音数据共840 min,其中男性460 min,女性380 min,对应的彝文有12 545个句子,不含13岁以下儿童和70岁以上老人,音频格式以WAV为主,彝文格式为TXT文件。实验数据集如表2所示。发音和词汇区别都以北部方言为参照对象[24],区分方法参考《中文语音识别系统通用技术规范》(GB/T 21023—2007),且忽略个体发音区别因素。情感词缀占比是指该方言样本数据中带情感词缀的句子数占句子总数的百分比;发音区别占比是指该方言样本数据中发音有区别的句子数占句子总数的百分比;词汇区别占比定义类似[25]。
| 图表编号 | XD00222684200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.10 |
| 作者 | 何俊、张彩庆、张云飞、张德海、李小珍 |
| 绘制单位 | 昆明学院信息工程学院、云南大学外国语学院、昆明学院信息工程学院、云南大学软件学院、昆明学院信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}