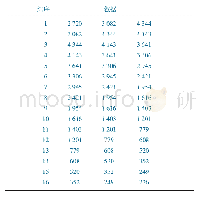
《表1 样本数据:基于神经网络的煤矿事故数量预测研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
GA-BP预测数据以2000—2018年共19年的煤矿事故发生数量为样本,采用每3年预测下一年的方式滚动输入数据,见表1。数据共分为16组,把1~13组作为训练组来训练网络,14~16组作为测试组,对应的2003—2015年的事故数量为训练组对应的输出层数值,用训练组和相应的输出数值来训练网络。网络训练完成后将测试组的数据输入,得到的输出数据与2016—2018年的实际数据的误差来判断由训练得到的网络能否准确预测对应年份的煤矿事故数量。因此,GA-BP的预测网络输入层节点个数为3,输出层节点个数为1,经过多次训练,最终隐含层确定为1层且在含有5个节点的时候预测误差达到期望值,即构建3-5-1的神经网络,得到的20个权值,6个阈值,遗传算法中的个体编码长度为26。本文采用matlab2016a进行计算,归一化函数采用mapminmax函数。遗传算法进化代数设为20,种群规模为10。得到的最优个体适应度值如图2所示,在经历过11次进化后达到稳定值,对应的由遗传算法得到的最优初始权值wij和wjk,以及阈值B1和B2分别为:
| 图表编号 | XD00221711900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.26 |
| 作者 | 白彦龙、陈昱、白长江、梁建明、西龙、薛玉壁、彭佳佳、王欣 |
| 绘制单位 | 河南省正龙煤业有限公司城郊煤矿、河南省正龙煤业有限公司城郊煤矿、河南省正龙煤业有限公司城郊煤矿、中国矿业大学(北京)、河南省正龙煤业有限公司城郊煤矿、河南省正龙煤业有限公司城郊煤矿、河南省正龙煤业有限公司城郊煤矿、河南省正龙煤业有限公司城郊煤矿 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}