《表2 数据集分布:基于不平衡大数据的CS-AdaBoost-DT模型在家电产品质检中的应用》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于不平衡大数据的CS-AdaBoost-DT模型在家电产品质检中的应用》
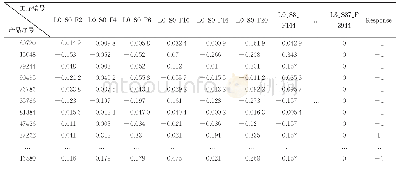
研究使用德国Bosch家电公司在Kaggle竞赛平台上公布的车间生产数据。数据主要包含:产品序号、工序编号、产品类别。每件产品均具有唯一编号,即表2中的产品序号;每个工序也具有唯一编号,如L0S8_F_144表示编号为0的生产线上,第8个站点上的第144道工序;产品类别对应于Response列,-1为合格品,1为不合格品。智能质检模型根据大量的产品数据进行学习与迭代,最终依据产品在各工序上的参数值对产品进行智能分类[25]。本文选取6 731件不合格品,36 781件合格品,二者分布比例为1.83:10;然后采用特征工程中XGBoost算法识别出不同工序的优先级别,最终保留排名前50的工序作为分类特征(如图2),处理后的部分数据见表2。
| 图表编号 | XD00221283700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.10 |
| 作者 | 吴增源、周彩虹、刘畅、郑素丽 |
| 绘制单位 | 中国计量大学经济与管理学院、中国计量大学经济与管理学院、上海应用技术大学电气与电子工程学院、中国计量大学经济与管理学院 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}