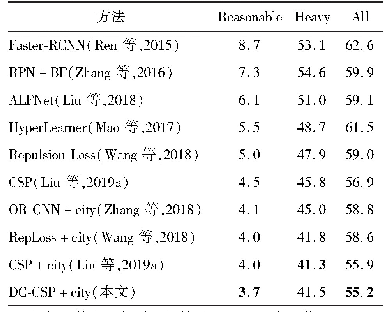
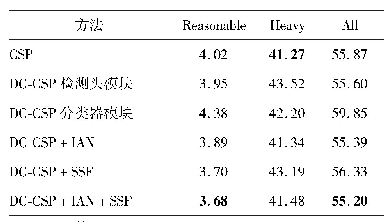
《表8 不同方法在Caltech数据集上的对数平均漏检率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:加粗字体表示各列最优结果,“+city”表示使用Cityper-sons数据集预训练模型作为初始化。
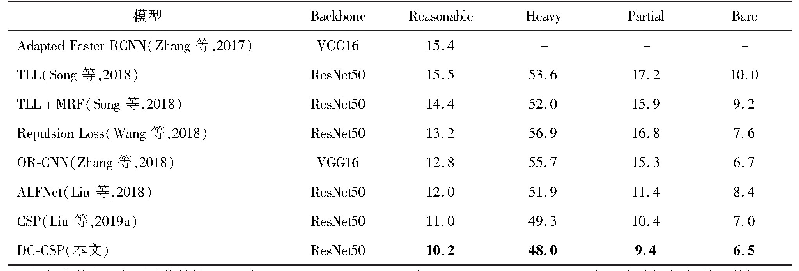
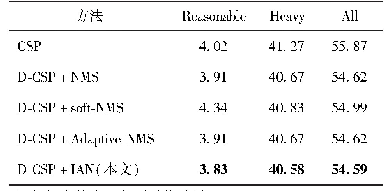
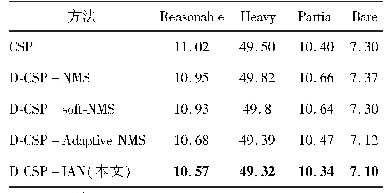
不同方法在Citypersons和Caltech数据集的实验结果(对数平均漏检率)如表7和表8所示。通过定量对比可以看出,相比于其他方法,使用本文方法的效果有明显提高。ALFNet(Liu等,2018)方法使用两阶段渐进定位,但仅能够实现一般场景下的行人检测,没有考虑相互遮挡行人的漏检和单个行人的错检问题。Repulsion Loss(Wang等,2018)以及OR-CNN(Zhang等,2018)均设计合理的损失函数来吸引或者排斥检测框,但都没有从根本上抑制相互遮挡行人框的删除,并且anchor学习难度大,造成性能提升很少。CSP(Liu等,2018)首次使用anchor-free思想进行行人检测,但存在置信度不精确的问题。本文方法基于anchor-free框架,添加密度图模块和分类器模块,提出SSF分数融合规则以解决置信度不精确的问题,并且设计IAN方法有效避免漏检和错检。在公开的行人数据集Citypersons上测试,本文方法在4个子集上均有1%左右的提升,表明本文方法可以有效处理各种不同场景。在Caltech数据集的实验中,为了获得更好的结果,使用Citypersons数据集预训练模型作为初始化进行训练,但仅在Reasonable和All子集上略有提升,这可能是该数据集分辨率不高并且大多数行人的尺寸较小所致。在Heavy子集上没有提升,原因是图像清晰度不高导致严重遮挡行人含有大量噪声,使得多任务训练更加困难,对其特征提取能力下降。
| 图表编号 | XD00216438900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.16 |
| 作者 | 甄烨、王子磊、吴枫 |
| 绘制单位 | 中国科学技术大学类脑智能技术及应用国家工程实验室、中国科学技术大学类脑智能技术及应用国家工程实验室、中国科学技术大学类脑智能技术及应用国家工程实验室 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}