《表3 基于隐变量模型算法的网络流量分类研究总结》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
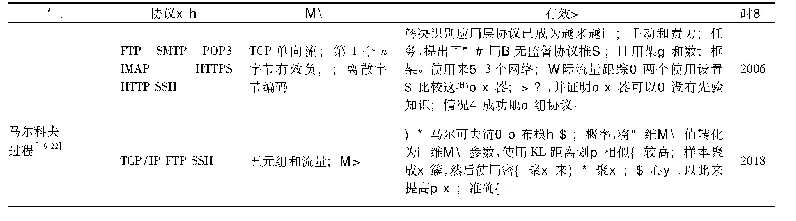
隐变量模型是一种统计模型,它把显变量和一组隐变量(或潜变量)联系起来,可以处理较为复杂的分布。文献中,当网络存在训练数据中没有的新型未知协议和应用时,流量分类算法准确率很低[18]由于协议与端口之间的关系恶化,识别应用层协议越来越费力。面对新型协议、应用时,由于没有特征匹配而无法识别,会被错误的分类到某一类训练数据的协议类别中,准确度大幅度下降。为了解决这个问题,文献[15]在提出了用无监督协议推理的通用架构和数学框架之后,又提出了3种无监督分类技术:字节偏移的产品分布,字节转换的马尔可夫模型和消息字符串的公共子字符串图的内容,用于捕获协议中流量信息的序列和结构。文献[21]通过马尔科夫模型[20]提取特征参数,识别流量应用类型,解决了传统分类方法依赖不稳定聚类算法的问题。文献[22]提出结合高斯混合模型和隐马尔科夫模型的新的流量分类模型,提高了对网络流量的监管能力。实验结果表明提出的新模型的参数选择方式,计算代价低,对协议和应用分类效果好,可实现流量中加密流量的有效识别与分类。文献[23]采用人工蚁群算法优化高斯过程,并对非线性的预测误差建模。针对当前隐变量模型的网络流量分类的特点以及有效性总结如表3所示。
| 图表编号 | XD00213587900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.01 |
| 作者 | 王方玉、张建辉、卜佑军、陈博、孙嘉 |
| 绘制单位 | 郑州大学中原网络安全研究院、信息工程大学、信息工程大学、信息工程大学、信息工程大学、郑州大学中原网络安全研究院、信息工程大学 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}