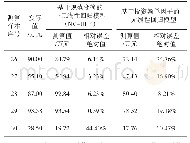
《表7 验证样本预测误差绝对值分布表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:N代表样本数量,ε代表误差。
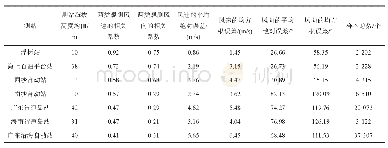
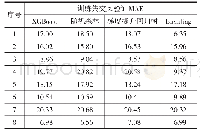
图3—图7结果表明,5类模型估算结果均存在误差。其中,各模型均出现高估幼龄林、低估成熟林的情况,而中龄林和近熟林相对其他龄组估测误差较小。随机森林回归模型在不同样本集中结果存在差异的原因是随机森林模型倾向于观测值较多的类别,在不同样本集中幼龄林样本数量相对较少且验证样本集中不同龄组样本数量也低于训练样本,导致验证样本林龄估算误差高于训练样本。为了进一步分析误差产生原因以及探讨各模型预测结果的误差分布,本研究将模型预测结果与实际结果作差值运算,并对结果取绝对值,以避免极值对于模型预测精度的影响。根据训练样本和验证样本的预测误差绝对值分布结果发现(表6和表7),对于训练样本,各模型预测误差绝对值|ε|≤5的累积百分比由高到低依次为:RF>BP=MARS>SVR>MLR,随机森林模型(RF)预测误差绝对值|ε|≤5表现明显优于其他反演模型;多元线性回归模型预测误差绝对值|ε|>5高达18个,预测误差绝对值与其他模型相比结果偏大。对于验证样本,各模型预测误差绝对值|ε|≤5的累积百分比由高到低依次为:SVR>RF=MARS>BP>MLR,支持向量机模型(SVR)预测误差绝对值|ε|≤5的累积百分比为0.76,与训练样本进行比较,可发现支持向量机回归模型(SVR)在训练样本中预测误差绝对值|ε|>5高达16个,训练样本与验证样本表现存在差异,模型稳定性不足,而随机森林模型(RF)的预测误差绝对值|ε|≤5的累积百分比为0.71,低于SVR的0.76,但是预测误差绝对值|ε|=0有5个且预测误差绝对值|ε|>5的数量仅比SVR多1个,随机森林模型(RF)稳定性高于支持向量机回归模型(SVR);多元线性回归模型(MLR)预测误差与训练样本表现类似,预测误差偏大。综上分析,虽然随机森林模型在验证样本中预测幼龄林误差高于其他非线性模型的预测误差,但是预测误差绝对值|ε|≤5的累积百分比在不同样本集中表现相似,预测误差偏小。因此在不同样本集中,随机森林模型为最佳林龄反演模型。
| 图表编号 | XD00212764900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.25 |
| 作者 | 岳继博 |
| 绘制单位 | 南京大学国际地球系统科学研究所、江苏省地理信息技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}