《表2 权重门槛设置实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
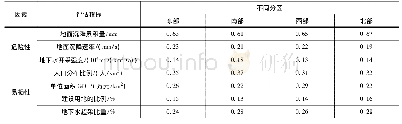
本小节旨在探究将历史测试语音信息纳入i-vector估计的潜在问题.首先,在通过MAP估计器给出两条测试语音来自同一人的概率作为权重时,虽然可以预期绝大多数来自不同人的测试语音所获的权重较低,但将它们用于BW统计量的计算仍会使系统性能有下降的趋势.与此同时,一些本身来自同一人的测试语音,却因为基线系统识别的效果不佳而被误分配了较低的权重,将这些测试语音用于BW统计量的计算会使系统性能趋于提升.为了揭示这两种相反的趋势对系统性能的影响,本文为用于计算BW统计量的历史测试语音权重设置门槛,当测试语音的权重低于这一门槛时,该测试语音将不再用于BW统计量的计算.表2列出了测试语音时长10s情形下,不同权重门槛值对应的实验结果以及被丢弃的历史测试语音数.
| 图表编号 | XD00212216200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 王铮、傅山 |
| 绘制单位 | 上海交通大学电子信息与电气工程学院、上海交通大学电子信息与电气工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}