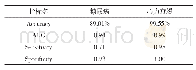
《表2 气体成分分析:Spark MLlib中决策树算法不同特征选择标准比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《Spark MLlib中决策树算法不同特征选择标准比较》
本实验进行时,规定了树的最大深度为8,最大箱化数为32.实验结果表明使用gini和entropy两种方法训练模型的时间差距很小,都保持了训练效率.原因在于虽然使用gini训练模型时不像entropy需要做对数运算,理论上使用gini的训练效率应高于使用entropy.但由于Spark自身特性,其拥有强大高速的计算处理能力,在树模型训练过程中是否有对数运算对其而言,差距几乎可以忽略不计.表2记录了使用基尼指数和信息熵两种分裂标准训练决策树模型时,两种方法在8个数据集上的平均分类精度.从表中所示数据来看,对于小数据集,使用基尼指数来划分训练数据集得到的模型其分类精度和使用信息熵训练所得模型的分类精度的差距不大.随着数据规模增大,使用信息熵作为划分准则其模型分类精度高于使用基尼指数训练的模型的分类精度,提高了约0.2.
| 图表编号 | XD00206772800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.25 |
| 作者 | 杜小芳、陈毅红 |
| 绘制单位 | 西华师范大学计算机学院、物联网感知与大数据分析南充市重点实验室、西华师范大学计算机学院、物联网感知与大数据分析南充市重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}