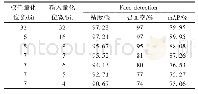
《表4 几种混合位宽量化法对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由于二值网络会降低模型的表达能力,研究人员提出,可以根据经验手工选定最优的网络参数位宽组合.Lin等人[74]在BNN[62]的基础上,提出把32-bit权重概率性地转换为二元和三元值的组合.Zhou等人[75]提出了Do Re Fa-Net,将权重和激活值分别量化到1-bit和2-bit.Mishra等人[76]提出了WRPN,将权重和激活值分别量化到2-bit和4-bit.K?ster等人[77]提出的Flexpoint向量有一个可动态调整的共享指数,证明16位尾数和5位共享指数的Flexpoint向量表示在不修改模型及其超参数的情况下,性能更优.Wang等人[78]使用8位浮点数进行网络训练,部分乘积累加和权重更新向量的精度从32-bit降低到16-bit,达到与32-bit浮点数基线相同的精度水平.除了权重和激活值,研究者们将梯度和误差也作为可优化的因素.这些同时考虑了权重、激活值、梯度和误差的方法的量化位数和特点对比可见表4.表中的W、A、G和E分别代表权重、激活值、梯度和误差.
| 图表编号 | XD00205362700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 高晗、田育龙、许封元、仲盛 |
| 绘制单位 | 计算机软件新技术国家重点实验室(南京大学)、计算机软件新技术国家重点实验室(南京大学)、计算机软件新技术国家重点实验室(南京大学)、计算机软件新技术国家重点实验室(南京大学) |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}