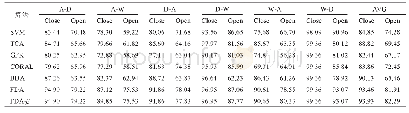
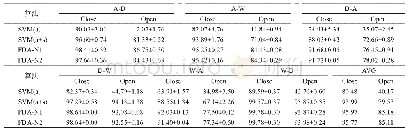
《表1 无监督设定下6个域转化实验的精度对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
同时报告了将数据转换为普通低维子空间的方法结果,这些算法都是在域自适应问题上表现非常显著的。在Office数据集[18]上对以下几个算法进行实验,包括迁移成分分析法(TCA)[7],实验中设定使用线性核函数进行映射,转化后的维为d=2/D,D为样本数据维度;构建了一条测地线来使源域靠近目标域的测地线流核(GFK),实验中利用子空间分歧度量(subspace disagreement measure,SDM)[9]和贪心算法求得这次实验中的最优子空间维度d*。此外,还有最小化源域和目标域的二阶统计特征的CORAL[11],实验用k近邻分类器,设置近邻k=1;在无监督情况下的实验,避免两个域之间适配条件分布和边缘分布被平衡对待而导致的实际问题中不平衡的问题,同样也对比了转移均衡的分布式适应算法(BDA),参考文献[8]中的设置,实验使用线性核,平衡因子μ=1,循环次数为10次。为了更好地分析本文方法FDA(fuzzy domain adaptation)算法不同形式的变换形式,FDA是拒绝所有奇异值的表现,源域中的类别对目标域所有样本开放,即β=∞;FDA-β表示允许有奇异值的出现,并且在参数β设置方面在实验部分有精确说明。将单独用源域数据训练的SVM分类器[17]作为比较对象,更好体现模糊域自适应的有效性。在使用开放集设置上[19],本文的实验报告如表1所示,明显可以看到模糊映射自适应方法的优越性,本文方法FDA在开放集和封闭集协议设定上都有显著的分类效果,比其他算法提升幅度更大。对于所有开放集合设定下的精度都小于封闭集合下的精度,但是本文方法在所有方法中仍然是表现最好的。
| 图表编号 | XD00204323100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.01 |
| 作者 | 刘晓龙、王士同 |
| 绘制单位 | 江南大学人工智能与计算机学院、江南大学江苏省媒体设计与软件技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}