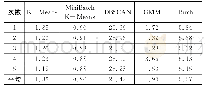
《表2 不同聚类算法的训练时间对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
s
在聚类算法的选择上,本文综合比较了K-Means聚类算法、Mini Batch K-Means算法、DBSCAN算法、GMM和Birch[17]算法的计算性能,实验结果如表2所示。可以发现GMM聚类算法在面对较大的数据集时,计算性能仅次于K-Means算法和Mini Batch K-Means算法。K-Means算法选择的初始聚类中心是随机的,在不同实验中可能产生不同的结果,不具备可重复性,因此并不适用于大型Web日志数据。Mini Batch K-means算法是K-Means算法的优化变种,训练时从数据集中随机抽取数据子集来减少计算时间,但是聚类效果也比K-Means算法稍差。DBSCAN算法是一种基于密度的聚类算法,其优点是对噪声鲁棒,能很好地拟合不同形状的数据。但是DB-SCAN算法的聚类速度较慢,无法满足Web缓存替换的高效性需求。Birch算法只需一遍扫描数据集就能建立CF Tree,并且对噪声鲁棒,聚类速度也比较快。但是对数据集的分布要求较高,不适合具有高维特征的数据集。而GMM使用均值和标准差进行计算,使得簇的形状更加灵活。而且GMM给出的是数据集中的项分布在不同簇的概率,因此可以对从Web日志数据中得到的概率进行进一步的处理,得到更好的预测效果。因此,综合考虑了计算速度和Web日志数据的特点,本文决定采用GMM来对已访问的Web日志数据进行聚类划分。
| 图表编号 | XD00203520800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.25 |
| 作者 | 唐榜、吴珏、杨福军、杨雷 |
| 绘制单位 | 西南科技大学计算机科学与技术学院、西南科技大学计算机科学与技术学院、中国空气动力研究与发展中心计算空气动力研究所、西南科技大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}