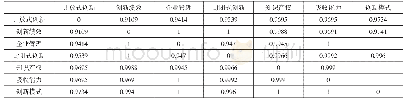
《表2 主要主题特征词的相异矩阵(部分)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
聚类分析是一个在数据集中寻找相似元素集合的无监督学习过程。通过对药物重定位领域主要主题特征词的聚类分析,可以寻找药物重定位领域主要主题特征数据集的“自然分组”,即主题类团。聚类分析的步骤为:首先,利用Bicomb对所有药物重定位研究文献进行主要主题特征词的向量表示,生成用于表示各特征词在文献中出现情况的文献-主要主题特征词矩阵。其次,将文献-主要主题特征词矩阵导入统计分析软件SPSS,计算主要主题特征词间Pearson相关系数,生成主要主题特征词的相似矩阵。考虑到相似矩阵中的0值较多,统计时容易引起误差太大,用1减去相似矩阵中各元素的值生成主要主题特征值的相异矩阵(表2)。在此基础上,选择聚类效果相对较好的组间连接聚类算法,测量区间设定为平方Euclidean距离,对主要主题特征值进行聚类得到如图4所示的聚类谱系结构。图4中,设定组间距离为20~25,可将主要主题特征词划分为6个类团,每个类团代表药物重定位研究领域的一个主要主题。
| 图表编号 | XD00203257700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.30 |
| 作者 | 邰杨芳、王帅、张芬利、于琦、贺培凤 |
| 绘制单位 | 山西医科大学管理学院、山西医科大学管理学院、山西医科大学管理学院、山西医科大学管理学院、山西医科大学管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}