《表2 不同工区各步骤加速结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
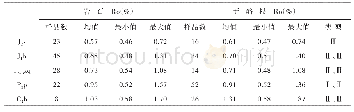
为了验证并行算法在性能上的提升情况,选取采样点均为1 001的不同工区,分别测试了优化冗余读取前后算法各部分在GPU与CPU平台上的计算时间,结果如表2所示。从局部来看,FFT过程有较多从硬盘拷贝数据的过程,这个过程会随着工区规模增加而明显影响程序的性能,因而FFT部分的加速比增幅略低。求Toeplitz矩阵过程中,各线程访问共享内存时存在难以优化的Bank conflict,这是提高其优化效率的主要瓶颈。利用雅可比迭代求预测算子时,每次需要对各线程迭代结果进行同步,之后在单线程中进行收敛判断,这是算法流程的固有瓶颈。
| 图表编号 | XD00201798300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.10 |
| 作者 | 杨先凤、贵红军、傅春常 |
| 绘制单位 | 西南石油大学计算机科学学院、西南石油大学计算机科学学院、西南民族大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}