《表5 基于不同组合模式的隐性引用句识别性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
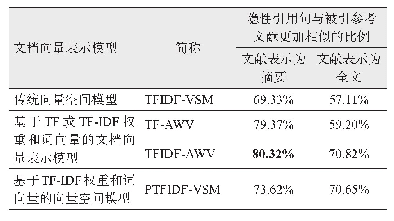
为了提高查全率,将基于不同文档向量表示模型的识别方法进行组合。首先,采用第一种文档向量表示模型从候选引用句中识别出引用句和非引用句;接下来,对第一步过滤出的非引用句采用第二种文档向量表示模型进行识别,从中识别出遗漏的隐性引用句。表5所示为不同组合模式的隐性引用句识别性能。可以看出,基于组合模式的隐性引用句识别能够进一步提高查全率,使识别的整体性能大大提高。最好的组合模式是基于TF-IDF权重和词向量的文档向量模型(TFIDF-AWV)与基于TF-IDF权重和词向量的向量空间模型(PTFIDF-VSM)的组合,当采用摘要表示文献时,F1值达到94%以上。这两个模型的组合顺序对识别性能有稍许影响,但两者区别不大,可忽略不计。
| 图表编号 | XD00212862300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.25 |
| 作者 | 金贤日、欧石燕 |
| 绘制单位 | 南京大学信息管理学院、南京大学信息管理学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}