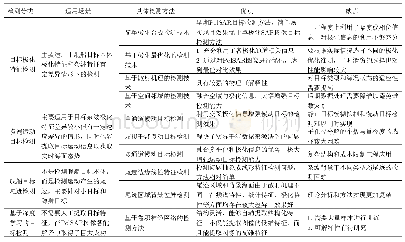
《表5 不同检测模型的优缺点及适用场景》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
2019年,Rahman等人[63]提出了直推学习方式来解决零样本目标检测问题。如图4所示,根据已知类预先训练好的模型给没有标记的未知类数据标注伪标签,然后将其加入训练集进行训练得到未知类检测模型。这种新的伪标记策略,将未标记的样本和相关的已知类动态关联起来,并使用一个固定的伪标记策略保留在源域获得的信息,有效地减少了对未知类的域偏移和模型偏差,在MS COCO数据集上获得了14.1%的m AP和37.2%的召回率。表5比较了不同的弱监督、少样本、零样本检测模型的优缺点及适用场景,在解决之前网络模型中出现的问题的同时,也会出现新的问题。由于可利用的监督信息很少,导致检测精度和召回率不佳,有待探索新的方法进一步提升此类网络模型的检测精度。
| 图表编号 | XD00201570700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.01 |
| 作者 | 罗会兰、彭珊、陈鸿坤 |
| 绘制单位 | 江西理工大学信息工程学院、江西理工大学信息工程学院、江西理工大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}