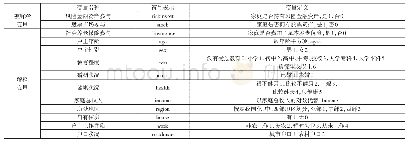
《表8 匹配前后变量对比:金融知识与家庭商业保险需求——基于中国家庭金融调查(CHFS)数据的分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《金融知识与家庭商业保险需求——基于中国家庭金融调查(CHFS)数据的分析》
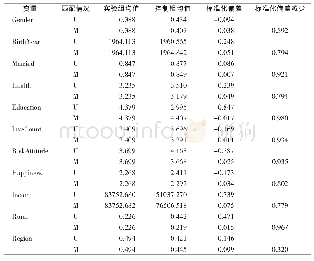
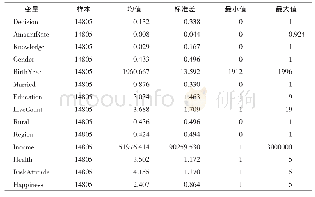
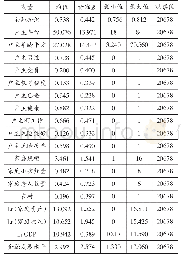
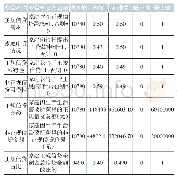
根据式(5)建立倾向性评分估计模型。经过倾向性评分估计后,对于满足重叠性假设的样本,本文选择使用1:1有放回匹配法进行匹配。由表7可知,匹配前倾向性评分模型的Chi2统计量为343.87,在1%的水平上显著,匹配后倾向性评分模型的Chi2统计量为5.13但不显著,说明倾向性评分模型在匹配前有效,在匹配后无效。对于变量的标准化偏差,匹配前标准化偏差的均值与中位数在20%~30%,匹配后标准化偏差均值与中位数在4%~5%,说明匹配算法减小了实验组与对照组各变量的标准化偏差。Rubin(2001)提出Rubin’s B统计量小于25且Rubin’s R统计量取值区间为[0.5,2],样本即被有效平衡。由表7可知,匹配前Rubin’s B统计量大于25,匹配后小于25,说明样本经过匹配后得到了很好的平衡。具体到每个变量(见表8),所有变量匹配后的标准化偏差大幅降低,且标准化偏差在10%以内。
| 图表编号 | XD00201428400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.20 |
| 作者 | 胡旻皓 |
| 绘制单位 | 上海财经大学统计与管理学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}