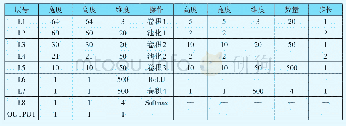
《表1 交通运输网络的数据结构操作效率比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
Dijkstra算法的关键步骤在于循环地从未标记节点中选取权重最小的弧段.因此,如何组织节点及其相关弧段的数据结构,使得每次都能最快找到未标记节点中权重最小的弧段成了实现算法的关键问题.Dijkstra算法的搜索范围可以看成以源节点为母节点向四周延伸的树状结构.此外,每次计算最短路径的源节点各不相同,因而该树状结构的母节点均不同,且母节点之下的子节点及其结构也都不同,这意味着每次计算都要重新组织一次数据的索引结构.同理,A*算法虽然增加了估算函数,其基本搜索过程仍然是从源节点指向目标节点的树状延伸过程.因此,无论是Dijkstra算法还是A*算法,都可以考虑将其网络数据的索引组织成树状结构.在道路交通网络的应用中,其网络数据呈现的是稀疏有向图的特点.每个节点的出度一般不超过5,大部分为2或者3,因此采用二叉树的索引结构的表示方式能够保证树的平衡性.目前,在最短路径搜索的研究中,最常见的几种网络数据组织结构主要有邻接矩阵、邻接表、链表等.表1比较了几种数据结构的操作效率.从表1可以发现,二叉树结构在查找、插入和遍历的效率方面优于其他数据结构.
| 图表编号 | XD00200371500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.30 |
| 作者 | 王亚、任燕、夏林元 |
| 绘制单位 | 遵义师范学院信息工程学院、遵义师范学院信息工程学院、中山大学地理科学与规划学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}