《表1 建筑专业评论高频语料库列表参考》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于网络评论语义分析的建筑大众印象研究——以广州恒大足球场为例》
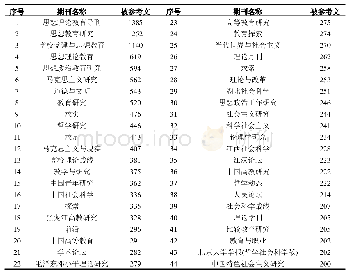
对专业评论数据进行基础查重和去重后,使用jieba代码库训练获取建筑专业评论高频语料。Jieba库采用隐马尔可夫模型(Hidden Markov Model,HMM)和维特比算法(Viterbi)进行基于汉字成词规律的深度学习训练,可获取未入词库记录的语料。HMM常用于一个系统中包含隐性状态的转移与表现概率的统计模型。Viterbi算法即通过动态规划求问题最佳解的一种节约算力的算法[9]。标准的Jieba库默认为标准现代汉语语料库,显然不能满足专业分析需求。本文采用Jieba库提供的词频-逆文件频率算法(Term Frequency-Inverse Document Frequency,TF-IDF)获取建筑专业语料[10,11]。原理是用4个隐含状态分别表示为单字成词、词组的开头、中部和结尾,通过已标注的分词训练集获取HMM模型的各项参数,再用Viterbi算法解释测试集,得出词频较高的建筑专业语料。即同个词在指定评论库中数量越多,且在非指定库中数量越少越能被提取。如下表1所示,筛选列举了几种类型建筑前30项建筑评论高频语料。这些语料根据其在各类型建筑中的权重调高词频,提高在网络评论检索中建筑专业语料的敏感度。同时,考虑以建筑造型、功能、环境等各构成要素为辅助分类标准[4]。针对建筑构成要素调整建筑专业高频语料的词频作为评论基准库,有助获取建筑对应要素的特定印象。
| 图表编号 | XD00199537700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.05 |
| 作者 | 林汨圣 |
| 绘制单位 | 华南理工大学建筑学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}