《表1 实验原水水质指标:基于案件描述注意力机制的刑事案件要素关系抽取》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文的实验语料是从百度新闻、新浪新闻和腾讯新闻等新闻网站上爬取下来的刑事案件描述文本共38 497篇。首先将爬取下来的篇章去重,然后进行分句处理,最后将句子进行分词和实体识别等语料预处理工作。将预处理之后80%的句子作为训练模型的目标数据集,20%的句子作为测试模型的测试数据集,将人工总结的案件描述信息作为辅助数据集。实验数据集情况如表1所示。
| 图表编号 | XD00198049000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.31 |
| 作者 | 李华琴、余正涛、赖华、郭军军 |
| 绘制单位 | 昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




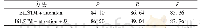
{kind=link}