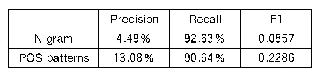
《表2 抽取式方法对比结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《融合复制机制和input-feeding方法的中文自动摘要模型》
/%
通过表2可见,基于生成式方法的模型明显优于抽取式方法的模型。因为抽取式模型是基于统计学的方法来进行建模,这种方法难以捕获更深层的语义信息,使得词与词之间以及上下文之间没有语义上的联系;同时,因为是以句子为单位抽取摘要,所以抽取得到的句子中含有许多与主题无关的非关键词,这也会影响模型的准确率。而对于生成式方法而言,由于网络具有学习特征表示的能力,能更好地为每个词之间建立语义层面的联系,从而增强了上下文的联系;且生成摘要能对主题信息进行更精确的表达,减少了冗余信息,从而提高了ROUGE得分。
| 图表编号 | XD00198017600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.05 |
| 作者 | 农丁安、欧阳纯萍、阳小华 |
| 绘制单位 | 南华大学计算机学院、南华大学计算机学院、南华大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}