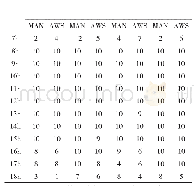
《表1 自动生成模板方法抽取效率对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
从表1可以看出,自动生成模板的方法对于单个网页抽取的运行时间较WEMLVF有明显提升,因为,在抽取过程中自动生成模板的方法不需要提取视觉特征。基于包装器归纳的方法运行速度比基于XPath的要快,因为基于包装器归纳的方法无需解析HTML源码构建DOM树,只需对网页进行分词得到Token序列来构建FST。
| 图表编号 | XD0054907900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 王宪发、郭岩、刘悦、俞晓明、程学旗 |
| 绘制单位 | 中国科学院大学计算机与控制学院、中国科学院计算技术研究所中国科学院网络数据科学与技术重点实验室、中国科学院计算技术研究所中国科学院网络数据科学与技术重点实验室、中国科学院计算技术研究所中国科学院网络数据科学与技术重点实验室、中国科学院计算技术研究所中国科学院网络数据科学与技术重点实验室、中国科学院计算技术研究所中国科学院网络数据科学与技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}