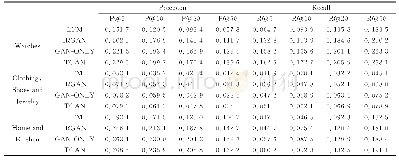
《表2 Recall性能对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
从表2中可以看出,在多数数据集上,使用采样方法平衡样本的分类算法在召回率上都要优于原始的分类算法。实际上,过采样方法通过增加少数类样本调整训练集的数据分布,强调了少数类对学习过程中的贡献度,从而扩张了少数类的决策空间,使得正类样本被正确预测的样本数增多,正类样本被错误预测的样本数减少,所以召回率Recall值比原始的分类结果要好。另一方面,LDSMOTE算法在11个数据集上取得了最优的Recall值,表明了它对少数类的识别率较大。
| 图表编号 | XD00197917100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.20 |
| 作者 | 许皓、孙廷凯 |
| 绘制单位 | 南京理工大学计算机科学与工程学院、南京理工大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}