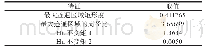
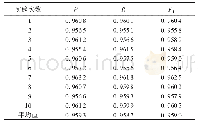
《表3 各试样最终裂隙率:基于视觉特征的仿冒域名轻量级检测技术》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由表4可以看出,文献[26-27,33]中提出的检测方法的内存开销较大,这是因为这些算法均需要收集域名的相关特征信息如Whois注册信息、DNS解析信息、网页信息、流量等进行检测判断。与文献[26-27,33]中的方法相比,基于编辑距离的方法和本文方法内存开销较小,这是因为其算法输入仅是域名字符串,不需要利用DNS解析信息等额外特征信息,能大幅减小存储开销,本文算法的“轻量级”也正是体现在此,算法仅利用域名的字符串进行判断。此外,相比原编辑距离算法(算法1),本文方法(算法2)在空间复杂度和时间效率上进行了优化,通过对算法结构的调整,将二维数组改为两个一维数组,其空间复杂度由O(m*n)减小到了O(min(m,n));通过删除字符串中相对应位置相同的字符后进行计算,使得计算量减小,所占内存减少,提高了计算效率,时间复杂度降为O(m1*n1)(m1≤m,n1≤n)。由表3也可看出,本文方法在内存开销、计算时间和F1这几个指标上都优于原编辑距离算法。综合考虑算法内存开销、计算时间和F1值等可知,本文提出的基于视觉特征的仿冒域名检测方法性能更优。
| 图表编号 | XD00197701500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.10 |
| 作者 | 朱怡、宁振虎、周艺华 |
| 绘制单位 | 北京工业大学信息学部、北京工业大学信息学部、北京工业大学信息学部 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}