《表1 滑坡数据集划分及统计信息》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
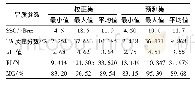
在深度学习中,需将样本数据划分为训练数据集、验证数据集和测试数据集。训练数据用于学习目标特征,验证数据用于选择表现最好的模型,测试数据用于对模型性能进行评价。本文中,为全面评价方法性能,根据滑坡类型分布和影像数据光谱特征相对均匀地划分数据集(见图1(b)),其中训练样本1 886处,验证样本86处,测试样本526处(见表1)。从滑坡的统计信息来看,滑坡最大边长为1 300 m,为充分训练滑坡和非滑坡区域,将滑坡区域的图片裁剪为2 000×2 000像素大小。
| 图表编号 | XD00197223800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.05 |
| 作者 | 巨袁臻、许强、金时超、李为乐、董秀军、郭庆华 |
| 绘制单位 | 成都理工大学地质灾害防治与地质环境保护国家重点实验室、成都理工大学地质灾害防治与地质环境保护国家重点实验室、南京农业大学作物表型组学交叉研究中心、中国科学院大学、中国科学院植物研究所植被与环境变化重点实验室、成都理工大学地质灾害防治与地质环境保护国家重点实验室、成都理工大学地质灾害防治与地质环境保护国家重点实验室、中国科学院大学、中国科学院植物研究所植被与环境变化重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}